It is tempting to turn this into a horse race. Shortcut beat Claude. Claude beat Copilot. Copilot beat ChatGPT. Done.
That framing is wrong.
The better question is the one finance teams actually care about at 11:40 PM: which system gives you outputs you can audit, reuse, and trust when the model still has to go to a VP before midnight? That is a harsher standard than “which model scored highest on a benchmark.” It is also the only standard that matters if the file has to survive review.
Wall Street Prep’s 2026 testing makes the gap plain. Shortcut led with a 5.9/10 score, followed by Claude at 5.5, Microsoft Copilot at 4.4, and ChatGPT at 2.5. Human analysts still scored much higher: 6.4 for lower-tier analysts, 7.9 for mid-tier, and 9.4 for top analysts. So yes, AI can help. No, it is not “replace the analyst” help. Not remotely.
And the gap is not academic. A 5.9/10 tool might help draft a debt schedule, clean assumptions, or explain a variance. It does not mean you should let it build an acquisition model end to end without review. A 47.78% portfolio return sounds flashy too, but portfolio selection is not the same job as building an audit-ready three-statement model. People keep jamming those together, and the result is bad buying decisions.
🥇 The 2026 ranking is real, but the scores need context
On the narrow question of AI financial modeling performance, Wall Street Prep’s test gives us the cleanest public comparison. Shortcut came first at 5.9/10. Claude was close behind at 5.5. Microsoft Copilot landed at 4.4. ChatGPT trailed at 2.5.
Useful result. Incomplete result.
What does a 5.9 actually buy you at 10:53 PM on a live deal? Usually better structure, cleaner handling of finance-specific prompts, and fewer obvious logic breaks than the other models in that test. It does not tell you whether the system can survive a real workflow with messy lender files, management assumptions that change twice in one evening, and a reviewer who wants to trace every output cell back to a formula chain.
This is where raw rankings get annoying. A benchmark score compresses several failure modes into one number. Finance teams do not experience failure as an average. They experience it when the model hardcodes a number where a formula should be, hides a circularity, builds a revenue schedule that looks polished but does not tie to units and price, or spits out an output tab nobody wants to defend in an IC meeting.
That last one happens more than people admit.
Shortcut’s lead matters, but the more useful question is why. The stronger tools tend to stay closer to spreadsheet logic, preserve structure, and produce work another analyst can check without playing detective for 40 minutes. That is why specialized finance products keep pulling ahead of general chat models in real production work.
Why specialized tools keep beating general models in production work
A generic model can sound smart. That is not the same as being useful in Excel.
Specialized financial AI tools are winning the contest that actually matters: can they generate formulas, preserve model logic, and leave an audit trail? That is where products such as Apers AI and Microsoft Copilot for Finance have an edge. The research brief points to Apers AI’s formula-first architecture for real estate private equity and to Copilot’s native Microsoft 365 integration, including the ability to work directly with Excel and run Python inside Excel cells.
Mechanism matters here. If a tool gives you a static NOI value, you cannot do much with it. If it gives you an Excel formula tied to lease-up assumptions, rent growth, concessions, and operating expenses, now you have something a team can inspect, change, and reuse next quarter. One is a chat answer. The other is a model component.
Picture a real estate associate updating a 27-tab underwriting model for a 312-unit multifamily deal. The useful system does not reply, “Projected Year 2 NOI is $4.8 million.” It writes the rent roll logic, links concessions to the assumptions tab, flags the vacancy step-up, and leaves the formula visible. If the VP asks why Year 3 margin expands by 140 basis points, the associate can answer inside Excel. If the model just hands back a number in a chat window, that conversation ends right there.
Copilot’s advantage is not that it is magically smarter than every other model. It sits next to the workflow people already use. For a finance team living in Excel, Outlook, Teams, and Power BI, that adjacency cuts friction. You can pull data, test formulas, draft commentary, and keep work inside a governed environment instead of copying numbers back and forth between tabs and chat windows.
I would take a slightly weaker model with transparent formulas over a more eloquent model with hidden logic every time. Black-box numbers are useless in institutional finance. Worse than useless, honestly. They create work for the next person.
Claude’s portfolio outperformance is interesting. It is not a free pass.
One of the flashier data points in this debate comes from a public 473-day trading comparison. Claude posted a 47.78% return since inception, ahead of Gemini at 33.08%, ChatGPT at 16.70%, and the VTI benchmark at 20.04%. That puts Claude ahead of the market by 27.74 percentage points and ahead of ChatGPT by 31.08.
Interesting? Yes.
Enough to crown a winner? No.
This is where finance readers should get suspicious. A single 473-day experiment is not the same thing as repeatable institutional performance. You would want the trade frequency, rebalance rules, prompt design, risk limits, turnover, drawdown profile, and whether the result survives a different market regime. You would also want to know whether this was a process edge or a favorable stretch with exposures that happened to work.
I’ve seen this move before in vendor decks: take one eye-catching return series, blur the operating details, and imply the model “understands markets.” Maybe it does. Maybe it got a nice run in one window. Those are not the same claim.
Still, I would not throw the result out. Claude has shown stronger reasoning in several finance-related tasks, and the trading outcome lines up with that broader pattern. In the research brief, Claude also shows up as stronger on complex financial logic, while ChatGPT performs better in some visualization-heavy workflows. Different jobs, different strengths.
The useful read is narrower than the marketing version. Claude appears better suited to reasoning-heavy financial tasks than ChatGPT in at least some real-world scenarios, and that may carry into portfolio construction or thesis evaluation. But portfolio selection, forecasting, and model-building are still different jobs. A model that picks ETFs decently is not automatically good at debt sculpting. Obvious, yes. Somehow still controversial.
Graph-of-Thought works. The reason it is not everywhere is cost and skill.
Most prompt advice in finance is fluff. “Be specific.” “Give context.” Fine. That is baseline hygiene, not a method.
The more interesting shift is from one-shot prompting to structured reasoning patterns. Research on prompt engineering techniques in finance reports that Graph-of-Thought methods improve accuracy by 15-25% in complex financial reasoning tasks and reduce hallucinations by 25-30% compared with baseline approaches.
Here is the version that matters in an actual workflow.
Chain-of-Thought asks the model to reason through steps in sequence. Graph-of-Thought goes further. It lets the model evaluate multiple branches, dependencies, and paths before settling on an answer. In finance, that matters when assumptions interact: revenue growth affects working capital, which affects financing needs, which affects interest expense, which loops back into cash flow.
A normal prompt often hides errors inside a smooth answer. Graph-of-Thought tends to expose branching logic. It is not magic. It just makes the breakpoints easier to inspect.
Suppose you want AI help on a mid-market acquisition model for a 14-location dental practice. A weak prompt asks for “a five-year forecast.” A Graph-of-Thought workflow breaks the task into branches: patient volume by site, payer mix, hygienist staffing ratios, capex by location, debt terms, downside case, and covenant sensitivity. The model works across those branches instead of pretending one linear answer can carry the whole thing.
That extra structure is why the accuracy gains show up. It is also why adoption is still low. According to the same finance prompt engineering review, only 10-15% of institutions have explored Graph-of-Thought, while 60-65% are experimenting with Chain-of-Thought. The cited cost is around $0.12 per query. That sounds trivial until an 11-person diligence team runs dozens of scenarios, exceptions, and review loops across a week. Then it is not trivial.
There is also a skill problem. Most teams do not know how to design these workflows cleanly, and bad Graph-of-Thought prompts can be worse than plain Chain-of-Thought. More branches do not automatically mean better logic. Sometimes they just mean a more expensive mess.
Use Graph-of-Thought when the answer has multiple dependencies, the cost of being wrong is high, and a human reviewer needs to inspect the path. Do not waste it on simple variance commentary or first-pass memo drafting.
The best prompt pattern is boring on purpose: Context Sandwich
The highest-performing prompt pattern in this research is not clever. It is structured.
The “Context Sandwich” framework combines role, task, and constraint. In practice, that means telling the model who it is acting as, what exact job it needs to do, and what boundaries it must respect. Finance people are already good at this. If you can write a month-end checklist or a clean SOP, you can write a decent prompt.
A weak prompt says: “Build a forecast for this company.”
A stronger prompt says: “Act as a corporate FP&A analyst. Build a 12-month revenue and EBITDA forecast for a regional HVAC distributor using the attached monthly sales history, preserve seasonality from the last 24 months, show assumptions separately, and output Excel-ready formulas only. Do not hardcode totals. Flag any missing driver data before forecasting.”
That is not fancy prompt engineering. It is operational clarity.
The research brief also identifies six useful prompt elements: role assignment, task statement, context, format requirements, examples, and constraints. That lines up with why Chain-of-Thought has spread further than Graph-of-Thought. It is easier to teach, easier to review, and easier to fit into normal finance work. Again, 60-65% of financial institutions are experimenting with Chain-of-Thought techniques.
One aside: a lot of “prompt engineering” content online is just people renaming common sense and sending an invoice. Context Sandwich is useful for a less glamorous reason. It maps neatly to how finance teams already document work, review work, and blame each other when work goes sideways.
Adoption is not failing because the models are bad. It is failing because the systems are messy.
This is the part vendors usually skip.
Across organizations, 88% use AI in at least one business function, but only 7% have fully scaled it enterprise-wide. Another 23% are scaling agentic AI systems. That gap tells you what is really happening: experimentation is easy; operational deployment is hard.
In finance, the blockers are familiar and boring. According to research on agentic AI in financial services, 48% of organizations cite governance concerns, 30% flag privacy issues, and 20% say their data is not ready for AI. None of that gets fixed by switching from ChatGPT to Claude or from Claude to Shortcut.
If your source data is split across five spreadsheets, two ERP exports, and one “final_v7_reallyfinal.xlsx” file on someone’s desktop, the model is not the main problem. Your process is.
That is why the McKinsey 3:1 rule cited here matters so much: high-performing firms invest three times more in process redesign than in software itself. I think that is the most useful statistic in this whole discussion. It explains why one team gets a faster close and cleaner forecast pack while another gets a pilot, a security review, and six months of drift.
A mid-market finance team that redesigns its close checklist, standardizes data definitions, adds review gates, and limits AI to scoped tasks will usually get more value than a team that buys the fanciest model and hopes it sorts out the chaos.
Boring answer. Correct answer.
What “moving beyond experimentation” actually looks like
By late 2025, 44% of finance teams had moved beyond experimentation into core-function deployment. That sounds aggressive until you look at the tasks involved.
Usually it is not “AI runs finance.” It is drafting first-pass variance explanations from monthly actuals, cleaning and categorizing GL exports, building scenario summaries for management review, checking formula consistency across large workbooks, and preparing forecast narratives from already-reviewed numbers.
Those are real gains. They save time. They also fit the current state of the tools.
Take a common case: a 9-person FP&A team at a manufacturing company needs to update a 13-tab forecast workbook every month. Copilot inside Excel can help identify broken links, draft commentary, and run Python-based checks on outliers. Claude can help reason through a margin bridge or pressure-test assumptions. A specialized finance tool can generate formula-based forecast components. But a controller or senior analyst still has to sign off on the final output.
That is the pattern I keep seeing. AI gets you from blank page to rough draft fast. Humans still do the last 20%, which is where most of the risk lives.
And that last 20% is not cosmetic. It is where someone notices that the working capital assumption still reflects Q2 seasonality, that the debt schedule forgot the amendment fee, or that management’s “temporary margin pressure” has now lasted three quarters. Models miss that stuff all the time. Humans do too, obviously. Just less cheerfully.
Agentic finance is coming slowly, not magically
The AI agent market is growing fast. Market estimates put it at $5.43 billion in 2024, rising to $7.92 billion in 2025, with a projected 45.82% CAGR from 2025 to 2034. And one Gartner-linked projection says 40% of finance departments will deploy autonomous agents by 2027.
Maybe. With conditions attached.
I would be careful with the phrase “autonomous agents,” especially in finance. The useful version is not a robot CFO. It is a bounded system that can perform judgment-based tasks under human oversight, with approval rules, exception handling, and logs. Remove those controls and you do not have automation. You have audit problems.
The same caution applies to projections that 60-80% of Tier-1 banks may deploy Graph-of-Thought systems by 2030 for 30-40% faster M&A due diligence. Possible, sure. But only if trust infrastructure gets built first: data lineage, prompt versioning, review layers, exception queues, and human override design.
Without that, “agentic workflow” is just a nice phrase on a slide.
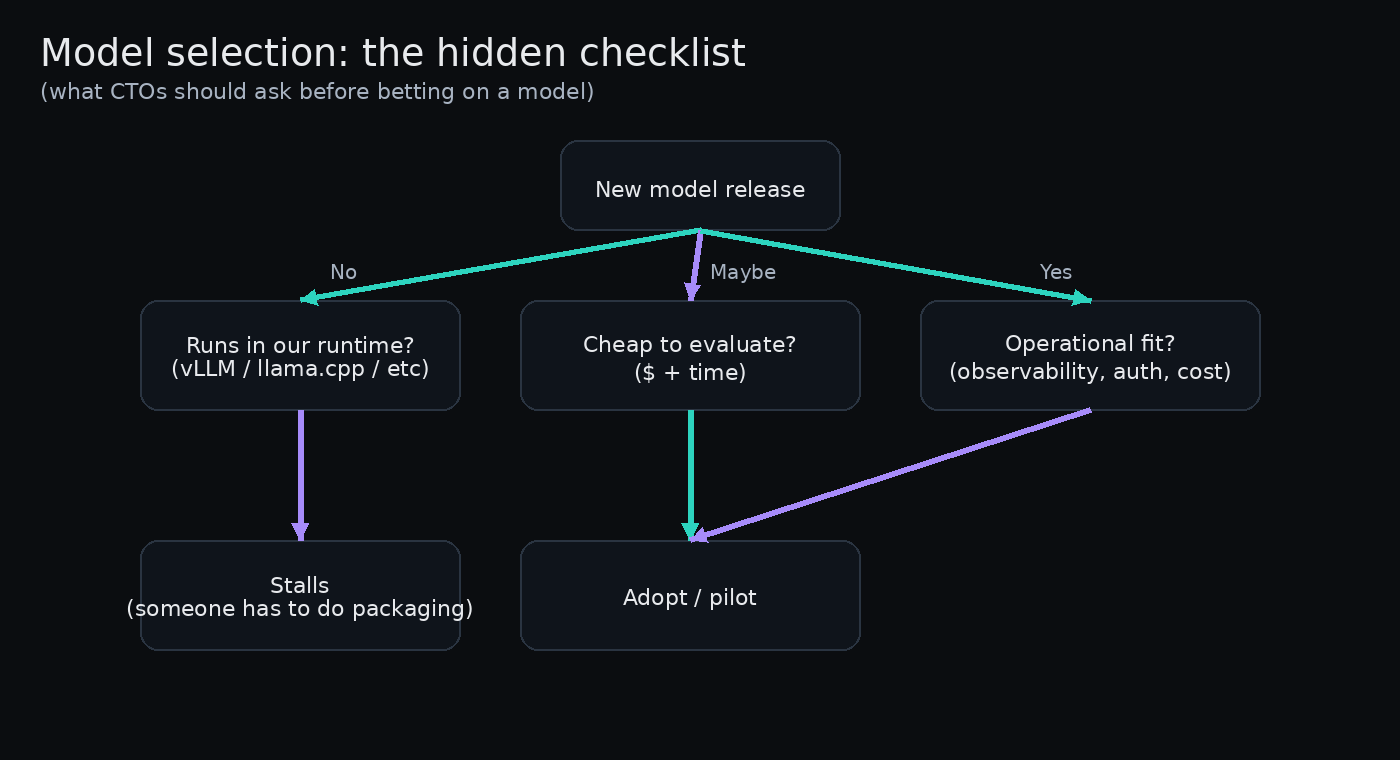
A practical deployment map for 2026
If you are a mid-market analyst, finance manager, or Excel-heavy operator, you do not need a winner. You need a decision lens.
Use general models for exploratory work. Claude, ChatGPT, and similar tools are useful when the task is open-ended and the cost of being wrong is low at the draft stage. Good examples: brainstorming drivers, summarizing filings, drafting management questions, sketching scenario logic, or turning a messy data export into a first-pass narrative.
Claude looks stronger for reasoning-heavy finance tasks, supported both by benchmark comparisons and by the more tentative 473-day trading experiment. ChatGPT still has value, especially where its analysis and visualization tooling fits the job. But neither should be treated as a final-answer machine.
Use specialized tools for auditable production work. If the deliverable needs to live in Excel, survive review, and get reused next quarter, specialized tools have the edge. Formula-first architecture, native spreadsheet integration, and enterprise controls matter more than conversational polish. This is where tools such as Apers AI and Microsoft Copilot for Finance make more sense than a generic chatbot.
And if the task involves multi-step dependencies, use structured prompting. Context Sandwich for normal work. Chain-of-Thought for calculations with several steps. Graph-of-Thought when the stakes justify the extra cost and setup.
Keep humans on final judgment. This is not ceremonial sign-off. It is the control layer.
Human analysts are still better at spotting bad assumptions, understanding business context, challenging management narratives, and deciding when a clean-looking output is actually nonsense. The Wall Street Prep scores already tell us that. Even the best AI tool still trails a low-tier human analyst.
So the practical stack in 2026 looks like this: AI for speed, specialized systems for structure, humans for judgment.
If you are evaluating tools right now, do not ask which model “wins finance.” Ask three narrower questions instead: Can we audit the output? Can we reuse it in our actual workflow? Can we trust it under deadline with a reviewer breathing down our neck?
That is a much less glamorous way to buy software. It is also the one that keeps you from explaining a hallucinated debt covenant to a VP at 11:58 PM.